
Transformer Architecture for Humans
An intuitive, text-first introduction to Transformer models written for technical leaders, engineers, and curious minds. This article explains how Transformers work using systems thinking and practical language, without equations or jargon, making the core mechanics of modern LLMs accessible through context and clarity.
TL;DR
- Transformers process all tokens in parallel, not one by one
- Self-attention lets each token decide what to focus on
- Layers refine meaning by reweighing contextual relationships
- These models learn patterns, not fixed grammatical rules
- You don’t need equations to understand them, just systems thinking
- This intuition improves prompting, architecture, and team decisions
Who this is for
Whether you’re building products, leading engineering teams, managing AI initiatives, or just curious about the tech powering ChatGPT and other large models, this article was written for you.
It’s especially crafted for:
- Technical leaders who care about AI systems, but also about people, delivery, and purpose.
- Engineers, architects, and designers working near LLMs.
- Curious thinkers who value clarity over complexity.
If you can follow a team, debug a process, or map out a system, you can understand Transformers.
Why Transformers Matter
Transformers are not just a model, they are a shift. They’re the reason we have modern language models, real-time translation, code completion, and AI that can reason across long contexts.
The entire modern LLM ecosystem is built on this architectural idea.
But What Is a Transformer?
A Transformer is a model that learns how parts of a sentence relate to one another, not just left-to-right, but all at once.
Imagine reading an entire paragraph instantly, then zooming in to understand each word in light of everything else around it. That’s what a Transformer does, and it does it for every word at the same time.
This is called Self-Attention. It’s the core idea.
What Self-Attention Really Means
Self-Attention lets each word (or token) ask:
“Who should I listen to, in this sentence, to understand who I am?”
- In the sentence “She gave the book to John because he asked for it,” the word “he” needs to look at “John” to make sense.
- Traditional models struggle with this. Transformers learn these relationships, across distance, position, ambiguity, and context.
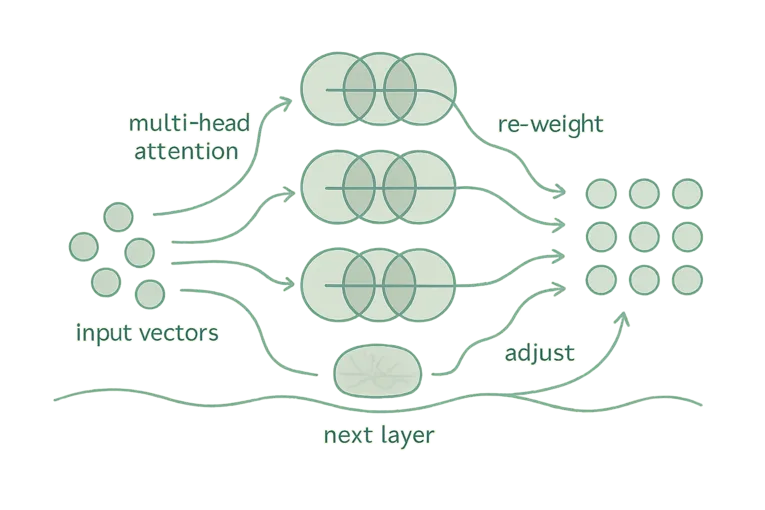
How It Works (Visually, Not Mathematically)
Every input token becomes a vector, a kind of coordinate in space. But instead of moving forward step by step, the model:
- Looks at all tokens at once (via multi-head self-attention)
- Weighs how much each other token matters for this one
- Adjusts its internal representation accordingly
- Passes that to the next layer to refine again
It’s a process of re-contextualization, repeated layer after layer.
You don’t need calculus to get this. You just need to imagine layers of meaning, reshaping themselves in relation to the whole.
It’s About Relationships, Not Rules
Transformers don’t store grammar books. They don’t follow step-by-step logic trees.
They learn patterns of usage by seeing billions of examples. And through attention, they figure out what’s important, what depends on what.
This makes them flexible, adaptive, and surprisingly good at generalizing, not because they memorize, but because they abstract.
Why This Matters in Practice
If you’re building anything with LLMs, from civic tech to customer service tools, here’s what you gain by understanding Transformer intuition:
- Better prompt design
- Realistic expectations about output limits
- Awareness of latency and scaling implications
- Empathy for what the model can and cannot “understand”
And if you’re leading teams:
- You’ll be able to ask better questions
- Build more responsible AI systems
- Guide architecture that matches real context, not just vendor hype
Key Takeaways
- Transformers process everything in context, not step by step
- They use Self-Attention to relate each token to all others
- They repeat this process through multiple layers, refining meaning
- Their power lies in pattern and relationship, not rules
You don’t need to code one. But if you understand how they think, you can design for them, or lead others who do.
Authored by Davi de Andrade Guides
Part of the series: “Thinking with Transformers”
Visit daviguides.github.io for more insights